|
I am a second-year PhD Student at MIT EECS advised by Vikash Mansinghka and Josh Tenenbaum. I am a member of the Probabilistic Computing Project in CSAIL and BCS. Previously I was a researcher at Vicarious AI where I worked with Miguel Lázaro-Gredilla and Dileep George, and engineer at Uber ATG. In Dec. 2017, I recieved a BS in Computer Science and Math from Carnegie Mellon.
|

|
|
|
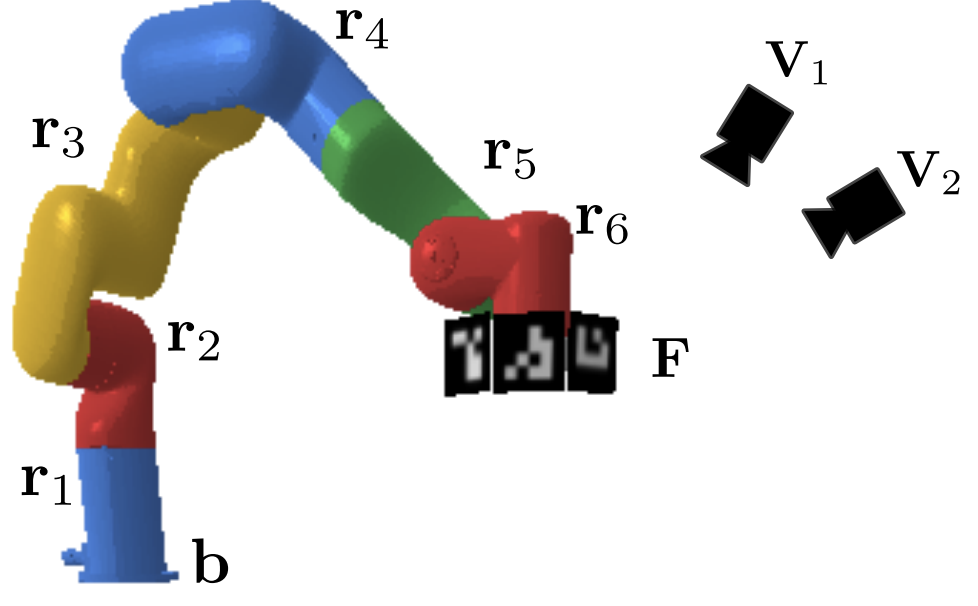 |
Nishad Gothoskar, Miguel Lazaro-Gredilla, Yasemin Bekiroglu, Abhishek Agarwal, Joshua B. Tenenbaum, Vikash K. Mansinghka, Dileep George ICRA, 2022 [PDF] In this work, we present a method for unsupervised learning of visual servoing that does not require any prior calibration and is extremely data-efficient. Our key insight is that visual servoing does not depend on identifying the veridical kinematic and camera parameters, but instead only on an accurate generative model of image feature observations from the joint positions of the robot. We demonstrate that with our model architecture and learning algorithm, we can consistently learn accurate models from less than 50 training samples (which amounts to less than 1 min of unsupervised data collection), and that such data-efficient learning is not possible with standard neural architectures. Further, we show that by using the generative model in the loop and learning online, we can enable a robotic system to recover from calibration errors and to detect and quickly adapt to possibly unexpected changes in the robot-camera system (e.g. bumped camera, new objects). |
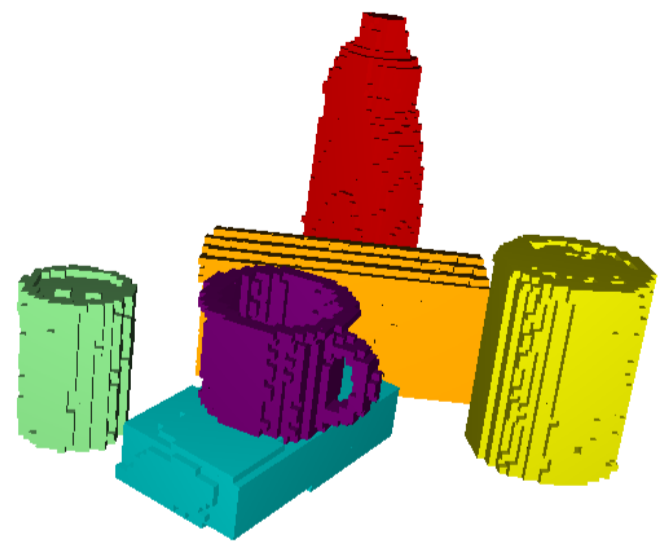 |
Nishad Gothoskar, Marco Cusumano-Towner, Ben Zinberg, Matin Ghavamizadeh, Falk Pollok, Austin Garrett, Dan Gutfreund, Joshua B. Tenenbaum, Vikash Mansinghka NeurIPS, 2021 [MIT News] [PDF] We propose a generative probabilistic programming-based architecture for modeling 3D objects and scenes, and use our architecture to do accurate and robust object pose estimation from RGBD images. |
 |
Dileep George, Rajeev V. Rikhye, Nishad Gothoskar,J. Swaroop Guntupalli, Antoine Dedieu, Miguel Lazaro-Gredilla Nature Communications, 2021 [PDF] Cognitive maps are mental representations of spatial and conceptual relationships in an environment, and are critical for flexible behavior. To form these abstract maps, the hippocampus has to learn to separate or merge aliased observations appropriately in different contexts in a manner that enables generalization and efficient planning. Here we propose a specific higher-order graph structure, clone-structured cognitive graph (CSCG), which forms clones of an observation for different contexts as a representation that addresses these problems. |
 |
Miguel Lazaro-Gredilla, Wolfgang Lehrach, Nishad Gothoskar, Guangyao Zhou, Antoine Dedieu, Dileep George AAAI, 2021 [PDF] Probabilistic graphical models (PGMs) provide a compact representation of knowledge that can be queried in a flexible way: after learning the parameters of a graphical model once, new probabilistic queries can be answered at test time without retraining. However, when using undirected PGMS with hidden variables, two sources of error typically compound in all but the simplest models (a) learning error (both computing the partition function and integrating out the hidden variables is intractable); and (b) prediction error (exact inference is also intractable). Here we introduce query training (QT), a mechanism to learn a PGM that is optimized for the approximate inference algorithm that will be paired with it. |
|
Template from here. |